DeepScaleR: Surpassing o1-Preview with a 1.5B Model by Scaling RL

引言
今天,一个名为’DeepScaleR: Surpassing O1-Preview with a 1.5B Model by Scaling RL’的项目引起了我的注意。该项目展示了如何通过分阶段强化学习(Scaling RL),将一个仅有 1.5B 参数的小模型,在数学推理任务上,提升到与 OpenAI 的 O1-preview 模型相当的水平,核心思想为Think Shorter, then Longer。
这个效果很令人振奋,同时在阅读作者在产生思路的历程中,我也有很多新的感悟,因此撰写此文分享我的理解和看法。(文末有真实本地部署体验示例)
项目背景:RL 规模化的挑战与机遇
同时,Deepseek-R1的技术报告与实验表明,直接在小模型上应用RL不如蒸馏有效。他们的消融实验显示,在Qwen-32B上应用RL在AIME上达到47%,而仅使用蒸馏则达到72.6%。 这里是个伏笔,造成了人们的误解:RL缩放只对大模型有益吗?
大型语言模型(LLM)在各种任务上展现出惊人的能力,但其训练成本也居高不下。强化学习作为一种强大的训练方法,可以进一步提升 LLM 的推理能力。然而,将 RL 应用于 LLM 面临着巨大的计算挑战。
DeepScaleR 项目的出发点,正是为了探索如何以更低的成本、更高效的方式,利用 RL 来提升 LLM 的推理能力。他们选择了一个 1.5B 参数的蒸馏模型 Deepseek-R1-Distilled-Qwen-1.5B 作为基础,通过一系列巧妙的设计,成功地将其在 AIME2024 数学竞赛上的 Pass@1 准确率从 28.8% 提升到了 43.1%,超越了 OpenAI 的 O1-preview 模型(40.0%)。
DeepScaleR 的核心技术
DeepScaleR 之所以能够取得如此显著的成果,主要得益于以下几个关键技术:
-
精心设计的数据集:
- 来源广泛: 涵盖 AIME(1984-2023)、AMC(2023 之前)、Omni-MATH 和 Still 等多个数学竞赛数据集。
- 三步处理:
- 答案提取: 使用 Gemini-1.5-pro-002 从官方解答中提取答案。
- 冗余去除: 构建 使用sentence-transformers/all-MiniLM-L6-v2 词嵌入的 RAG 来检索去除重复问题,并检查训练集和测试集之间的重叠,防止数据污染。
- 不可分级问题过滤: 过滤 那些 sympy 无法计算评估的问题,因为需要引入 LLM 评判,减慢训练速度并增加LLM噪声。
- 最终规模: 约 40,000 个高质量的问题-答案对。
-
高效的奖励函数:
- 采用 Outcome Reward Model (ORM, 结果奖励模型),避免奖励黑客攻击。
- 奖励规则简洁明了:
- 1:答案通过 LaTeX/Sympy 检查。
- 0:答案错误或格式不正确。
-
迭代式上下文长度扩展:
使用了DeepSeek的GRPO算法,但分为2个步骤进行训练(8K->16/24K)
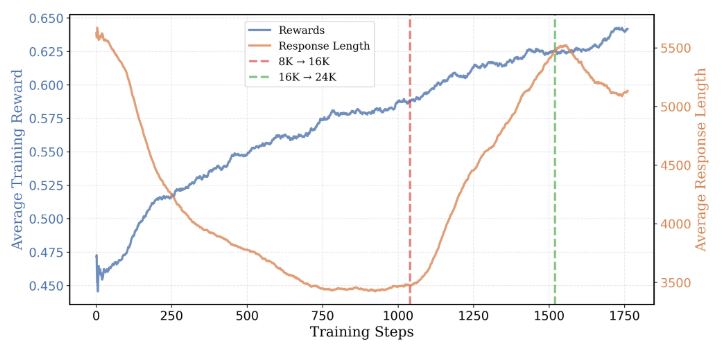
- 核心思想:
Think Shorter, then Longer - 8K 启动:
- 初始阶段使用 8K 上下文,训练更高效,模型更专注。
- AIME Pass@1 从 22.9% 提升到 33.9%。
- 平均响应长度从 5,500 tokens 减少到 3,500 tokens。
- 16K 扩展:
- 当 8K 训练达到瓶颈时,扩展到 16K 上下文。
- AIME Pass@1 进一步提升到 38%。
- 平均响应长度增加到 5,500 tokens。
- 24K 突破:
- 最后阶段扩展到 24K 上下文,实现最终突破。
- AIME Pass@1 达到 43.1%。
- 优势:
- 相比直接从 16K 或 24K 训练,大大降低了计算成本。
- 逐步引导模型学习更有效的推理模式。
- 核心思想:
实验结果与分析
DeepScaleR 在多个数学推理基准测试上进行了评估,包括 AIME 2024、AMC 2023、MATH-500、Minerva Math 和 OlympiadBench。结果表明:
- 全面超越基线模型: DeepScaleR 在所有测试中均显著优于 Deepseek-R1-Distill-Qwen-1.5B 基线模型。
- 媲美大型模型: 在 AIME2024 上,DeepScaleR 的 Pass@1 准确率(43.1%)超越了 OpenAI 的 O1-preview 模型(40.0%),且参数量仅为后者的一个零头。
- 超越学术界成果: DeepScaleR 的性能也优于 rSTAR、Prime 和 SimpleRL 等基于 7B 模型进行 RL 微调的学术成果。
下面是 DeepScaleR 与其他模型在各项测试上的 Pass@1 准确率对比(已验证分数为下划线):
| Model | AIME 2024 | MATH 500 | AMC 2023 | Minerva Math | OlympiadBench |
|---|---|---|---|---|---|
| Qwen-2.5-Math-7B-Instruct | 13.3 | 79.8 | 50.6 | 34.6 | 40.7 |
| rStar-Math-7B | 26.7 | 78.4 | 47.5 | - | 47.1 |
| Eurus-2-7B-PRIME | 26.7 | 79.2 | 57.8 | 38.6 | 42.1 |
| Qwen2.5-7B-SimpleRL | 26.7 | 82.4 | 62.5 | 39.7 | 43.3 |
| DeepSeek-R1-Distill-Qwen-1.5B | 28.8 | 82.8 | 62.9 | 26.5 | 43.3 |
| Still-1.5B | 32.5 | 84.4 | 66.7 | 29.0 | 45.4 |
| DeepScaleR-1.5B-Preview | 43.1 | 87.8 | 73.6 | 30.2 | 50.0 |
| O1-Preview | 40.0 | 81.4 | - | - | - |
关键发现与启示
DeepScaleR 项目的成功,为我们带来了以下几个重要的启示:
- 实验出真知: 作者在AIME2024上评估Deepseek-R1-Distilled-qwen-1.5B时发现,错误响应的token数量是正确响应的三倍(20,346 vs. 6,395),这表明较长的响应通常导致错误结果。过早使用长上下文窗口进行训练可能低效,因为大部分token被浪费了。此外,冗长的响应存在重复模式,未对有效的链式思维推理(CoT)做出实质性贡献。从而产生了从8K开始训练的思路,实验结果表明这是正确的!
- 不要迷信权威: 传统的观点认为,RL 规模化只适用于大型模型。DeepScaleR 证明,通过高质量的 SFT 数据蒸馏和精心设计的 RL 训练,小模型也能获得显著的推理能力提升。因此,即使是DeepSeek或者顶会的分析论文结论,也不如真正实践更重要!小模型选择RL/蒸馏?8K还是16K?等等
- 迭代式上下文长度扩展是有效的: DeepScaleR 的实验表明,逐步增加上下文长度,可以更高效地利用计算资源,引导模型学习更有效的推理模式。
个人思考与展望
DeepScaleR 项目给我最大的触动,是它证明了“小而美”的模型也能通过巧妙的训练方法,达到甚至超越大型模型的效果。这对于资源有限的研究者和开发者来说,无疑是一个巨大的鼓舞。
未来,我期待看到更多类似 DeepScaleR 的工作,探索更高效、更低成本的 LLM 训练方法。同时,我也希望 DeepScaleR 项目能够继续完善,例如:
- 扩大数据集规模: 40,000 个问题-答案对仍然相对较小,进一步扩充数据集有望带来更大的提升。
- 尝试不同的基础模型: Deepseek-R1-Distill-Qwen-1.5B 是一个很好的起点,但尝试其他基础模型可能会带来新的发现。
- 使用在Agent领域: 将赋予Agent逐步推理的能力,从而做出更加准确的动作判断。
总之,DeepScaleR 项目是一个令人兴奋的进展,它为我们展示了小模型在 RL 领域的巨大潜力。我相信,随着技术的不断发展,我们将会看到更多小模型在各种任务(推理)上大放异彩。
本地部署体验
这里感谢朋友BobMaster及时提供的本地部署对话demo,刚刚发布便本地部署体验,让我们一起看看这个1.5B的小家伙效果如何!
这里采用的是LM Studio && llama.cpp进行本地部署。 DeepScaleR的量化版本由LM Studio官方提供: Hugging Face Link
- 经典问题:
How many 'r' in word 'strawberry'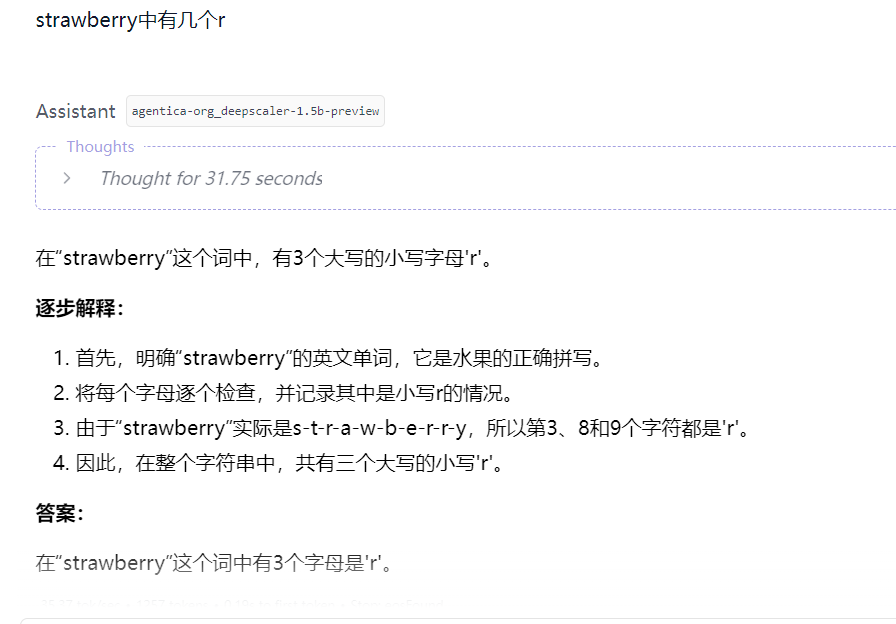
- 数学问题:
0.9999 与 1 的关系

- 代码生成:
制作贪吃蛇游戏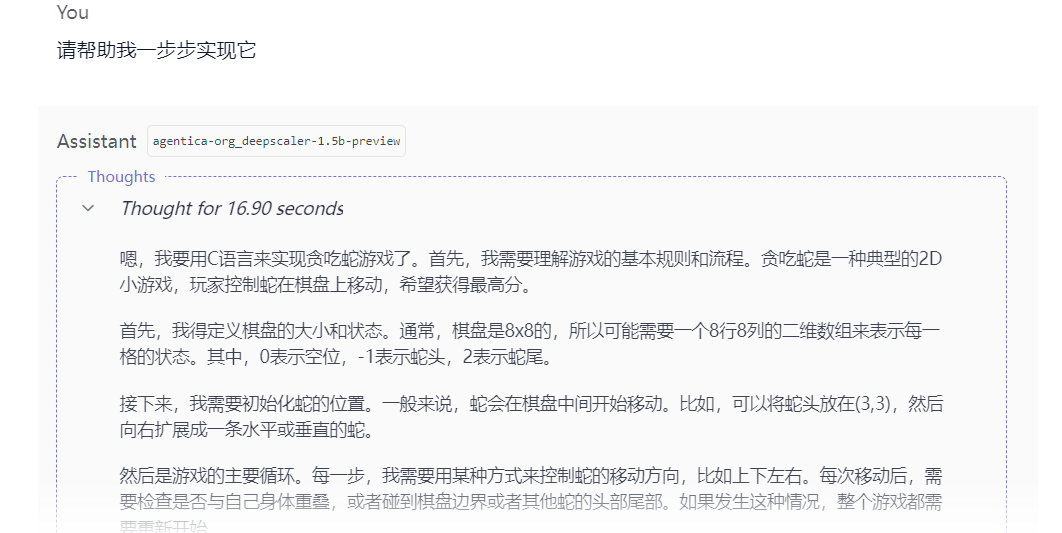
1. Commenters are absolutely anonymous.
2. You'll receive email notifications for replies if you provide an email address (optional).
3. I will also receive a notification and try to reply in time.