Paper Reading: UI-TARS: Pioneering Automated GUI Interaction with Native Agents


背景定位
核心问题
这篇论文试图解决的核心问题是开发一种能够像人类一样与图形用户界面(GUI)进行交互的自动化智能体(agent)。现有的GUI智能体大多依赖于商业模型(如GPT-4o)和专家手工设计的提示(prompt)及工作流,这些方法在面对复杂任务或动态变化的环境时容易失败,且难以扩展和适应。
细分方向
该研究属于计算机视觉(CV)和自然语言处理(NLP)的交叉领域,同时也涉及到强化学习的思想,因为智能体需要根据环境反馈进行学习和决策。
与现有研究的关键区别
与现有研究的关键区别在于,UI-TARS是一个端到端的原生GUI智能体模型,它不依赖于复杂的商业模型和手工设计的提示,而是直接以界面截图作为输入,通过增强的感知能力、统一的动作建模、系统2推理以及迭代训练等创新方法,实现了对GUI的高效交互和任务执行。
方法解析
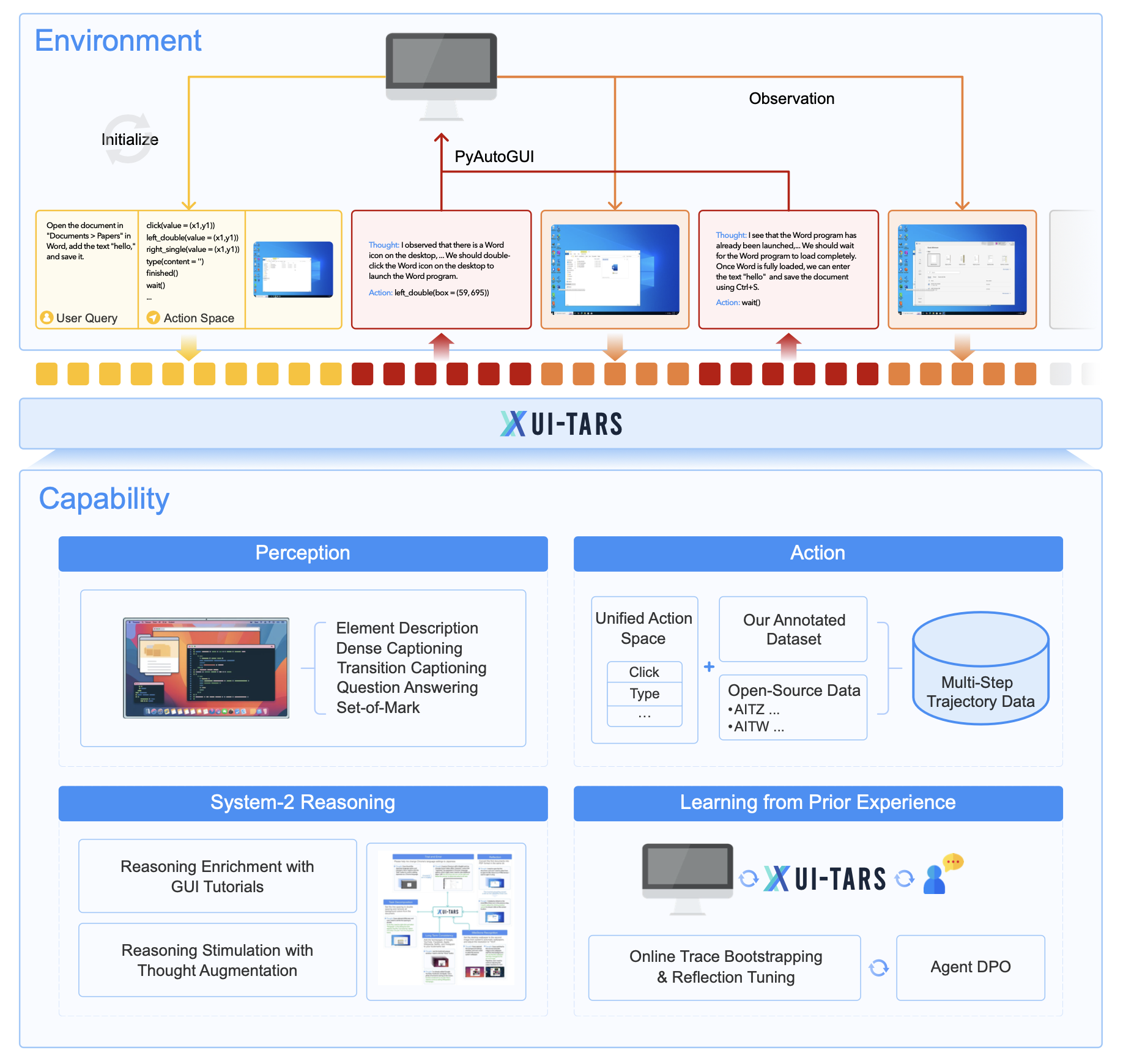
核心创新点
- 增强的感知能力:通过大规模的GUI截图数据集,训练模型对UI元素进行上下文感知的理解和精确描述,包括元素描述、密集字幕生成、状态转换字幕生成、问答等任务,以提高对GUI界面的理解能力。
- 统一的动作建模:设计了一个统一的动作空间,将不同平台上的语义等价动作标准化,并通过大规模的动作轨迹数据,提高模型在多步执行中的准确性和可靠性。
- 系统2推理:将系统2推理融入模型,通过注入任务分解、长期一致性、里程碑识别、试错和反思等多种推理模式,使模型在复杂任务中能够进行更深入的思考和决策。
- 迭代训练与反思调整:通过在虚拟机上自动收集、过滤和反思优化新的交互轨迹,解决数据瓶颈问题,使模型能够从错误中学习并适应未预见的情况,实现持续改进。
关键公式或算法
-
动作概率分布公式:
\[P(t_n, a_n | instruction, t_1, a_1, \dots, (o_{n-i}, t_{n-i}, a_{n-i})_{i=1}^{N}, o_n)\]其中,$t_n$ 表示在第 $n$ 步的思考过程(thought),$a_n$ 表示在第 $n$ 步的动作,$instruction$ 是初始任务指令,$o_i$ 是第 $i$ 步的观察(设备截图),$N$ 是考虑的最近交互步数。这个公式体现了模型在每一步决策时,不仅考虑当前的观察和任务指令,还会结合之前的思考和动作历史,以生成更合理的思考和动作。
-
直接偏好优化(DPO)公式:
\[L_{DPO}(\theta) = - \mathbb{E}_{\tau} \left[ \log \sigma\left( \beta \log \pi_{SFT}(a_{\tau'}|s_{\tau}) \pi_{\theta}(a_{\tau'}|s_{\tau}) - \beta \log \pi_{SFT}(a_{\tau}|s_{\tau}) \pi_{\theta}(a_{\tau}|s_{\tau}) \right) \right]\]其中,$\tau$ 表示有错误修正对的时间步,$\pi_{\theta}$ 表示优化后的策略,$\pi_{SFT}$ 表示监督微调(SFT)策略,$\beta$ 是控制优化策略与SFT策略之间差异的超参数。这个公式通过比较修正后的动作 $a_{\tau’}$ 和原始错误动作 $a_{\tau}$ 的概率,来优化模型,使其更倾向于选择正确的动作。
验证方法的有效性
主要实验设置
- 数据集:使用了大规模的GUI截图数据集,包括从网站、应用程序和操作系统中收集的截图及其元数据。
- 基线模型:与多种商业模型(如GPT-4o、Claude-3.5-Sonnet等)和学术模型(如Aguvis、OS-Atlas等)进行比较。
- 评估指标:根据不同的实验任务,使用了准确率、ROUGE-L、动作匹配分数等指标。
关键数据结果
- 在OSWorld基准测试中,UI-TARS-72B在50步预算下得分为24.6,在15步预算下得分为22.7,均优于Claude的22.0(50步)和14.9(15步)。

- 在AndroidWorld基准测试中,UI-TARS-72B得分为46.6,超过了GPT-4o的34.5。
- 在ScreenSpot Pro基准测试中,UI-TARS-72B得分为38.1,是当前最佳结果。
- 在VisualWebBench基准测试中,UI-TARS-72B得分为82.8,高于GPT-4o的78.5。
消融实验或可视化分析
进行了消融实验,比较了系统1(直接产生动作)和系统2(先进行推理再选择动作)推理对模型性能的影响。结果表明,在有足够候选输出的情况下,系统2推理能够显著提高模型在复杂任务中的性能,尤其是在未见过的任务(out-of-domain)中。
批判性思考
潜在局限或风险
- 虽然UI-TARS在多个基准测试中表现出色,但这些测试可能无法完全覆盖所有实际场景中的复杂性和多样性。在真实世界的应用中,GUI的界面和任务可能会更加复杂和多变,模型可能需要进一步的优化和调整。
- 迭代训练和反思调整依赖于大量的虚拟机资源和人工标注数据,这可能会限制模型的可扩展性和实际应用中的成本效益。
- 系统2推理虽然提高了模型的决策能力,但在某些情况下可能会导致推理过程过于复杂,从而影响模型的效率和响应速度。
实验结果是否充分支持结论
从实验结果来看,UI-TARS在多个关键指标上都取得了显著的提升,尤其是在复杂的任务和基准测试中,这表明其方法在提高GUI智能体的性能方面是有效的。然而,为了更全面地验证结论,可能还需要在更多实际应用场景中进行测试,以评估模型在面对真实世界中的各种挑战时的表现。
值得关注的延伸方向
- 一个可能的延伸方向是进一步探索如何将主动学习和终身学习机制融入到UI-TARS中,使模型能够更自主地从与环境的交互中学习和适应,减少对人工标注数据的依赖。
- 研究如何优化系统2推理的效率,使其在保证决策质量的同时,能够更快地响应用户的需求,也是一个重要的研究方向。
应用连接
实际应用场景
UI-TARS可以应用于多种需要自动化GUI交互的场景,例如:
- 软件测试自动化:自动检测和修复软件中的问题。
- 办公自动化:如文档处理、数据输入等。
- 智能客服:自动解决用户在软件使用中遇到的问题。
- 移动设备自动化操作:帮助用户更高效地使用移动设备。
- 辅助工具开发:帮助残障人士或老年人更方便地使用计算机和移动设备。
复现结果所需的资源
- 硬件资源:由于模型规模较大,需要高性能的计算设备,如具有强大GPU的服务器,以及大量的存储空间来存储训练数据和模型参数。
- 软件资源:需要安装深度学习框架(如PyTorch或TensorFlow)和相关的依赖库,以及用于数据处理和模型训练的代码。
- 数据资源:需要收集和整理大规模的GUI截图数据集,包括从不同网站、应用程序和操作系统中获取的截图及其元数据,同时需要借助大量人工来对数据进行处理和优化。
- 人力成本:需要专业的研究人员和工程师来设计和优化模型架构、训练过程和数据处理流程,同时还需要标注人员来对数据
1. Commenters are absolutely anonymous.
2. You'll receive email notifications for replies if you provide an email address (optional).
3. I will also receive a notification and try to reply in time.